bahmanm
Husband, father, kabab lover, history buff, chess fan and software engineer. Believes creating software must resemble art: intuitive creation and joyful discovery.
Views are my own.
- 15 Posts
- 74 Comments
Joined 1 year ago
Cake day: June 26th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.


 151·10 months ago
151·10 months agoThanks! So much for my reading skills/attention span 😂
Which Debian version is it based on?
RE Go: Others have already mentioned the right way, thought I’d personally prefer
~/opt/goover what was suggested.
RE Perl: To instruct Perl to install to another directory, for example to
~/opt/perl5, put the following lines somewhere in your bash init files.export PERL5LIB="$HOME/opt/perl5/lib/perl5${PERL5LIB:+:${PERL5LIB}}" export PERL_LOCAL_LIB_ROOT="$HOME/opt/perl5${PERL_LOCAL_LIB_ROOT:+:${PERL_LOCAL_LIB_ROOT}}" export PERL_MB_OPT="--install_base \"$HOME/opt/perl5\"" export PERL_MM_OPT="INSTALL_BASE=$HOME/opt/perl5" export PATH="$HOME/opt/perl5/bin${PATH:+:${PATH}}"Though you need to re-install the Perl packages you had previously installed.
 3·10 months ago
3·10 months agoFirst off, I was ready to close the tab at the slightest suggestion of using Velocity as a metric. That didn’t happen 🙂
I like the idea that metrics should be contained and sustainable. Though I don’t agree w/ the suggested metrics.
In general, it seems they are all designed around the process and not the product. In particular, there’s no mention of the “value unlocked” in each sprint: it’s an important one for an Agile team as it holds Product accountable to understanding of what is the $$$ value of the team’s effort.
The suggested set, to my mind, is formed around the idea of a feature factory line and its efficiency (assuming it is measurable.) It leaves out the “meaning” of what the team achieve w/ that efficiency.
My 2 cents.
Good read nonetheless 👍 Got me thinking about this intriguing topic after a few years.
This is fantastic! 👏
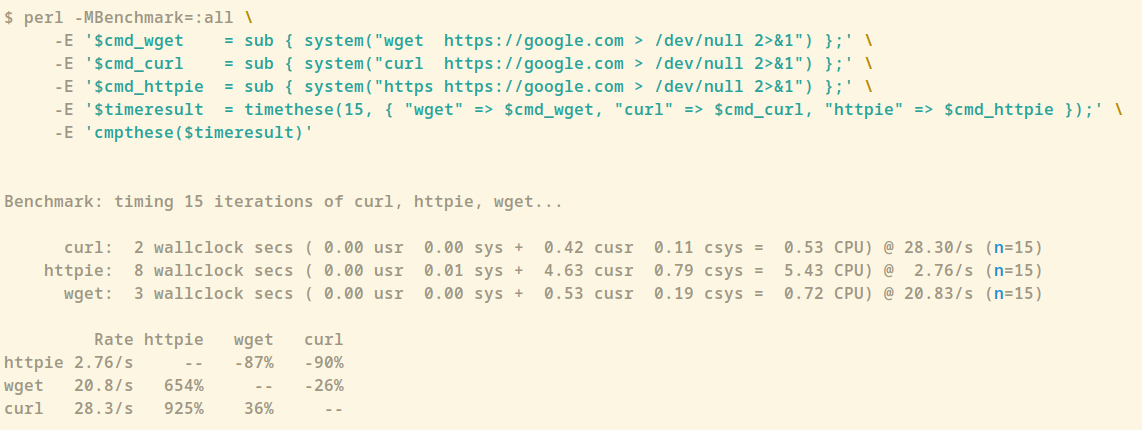
I use Perl one-liners for record and text processing a lot and this will be definitely something I will keep coming back to - I’ve already learned a trick from “Context Matching” (9) 🙂
That was my case until I discovered that GNU tar has got a pretty decent online manual - it’s way better written than the manpage. I rarely forget the options nowadays even though I dont’ use
tarthat frequently.
TBH I use whatever build tool is the better fit for the job, be it Gradle, SBT or Rebar.
But for some (presumably subjective) reason, I like GNU Make quite a lot. And whenever I get the chance I use it - esp since it’s somehow ubiquitous nowadays w/ all the Linux containers/VMs everywhere and Homebrew on Mac machines.
A bit too long for my brain but nonetheless it written in plain English, conveys the message very clearly and is definitely a very good read. Thanks for sharing.
That single line of Lisp is probably
(defmacro generate-compiler (...) ...)which GCC folks call every time they decide to implement a new compiler 😆
When i read the title, my immediate thought was “Mojolicious project renamed? To a name w/ an emoji!?” 😂
We plan to open-source Mojo progressively over time
Yea, right! I can’t believe that there are people who prefer to work on/with a closed source programming language in 2023 (as if it’s the 80’s.)
… can move faster than a community effort, so we will continue to incubate it within Modular until it’s more complete.
Apparently it was “complete” enough to ask the same “community” for feedback.
I genuinely wonder how they managed to convince enthusiasts to give them free feedback/testing (on github/discord) for something they didn’t have access to the source code.
PS: I didn’t downvote. I simply got upset to see this happening in 2023.

I’ve been using sdkman for about a decade now and am totally pleased w/ it. It does a very good job of managing JDK versions for you and much more, eg SBT, Gradle, Scala, Groovy, Leiningen, SpringBoot, …
Now, technically you could use sdkman in your CI/CD pipeline too but I’d find it a strong smell. I’ve always used dedicated images pre-configured for a particular JDK version in the pipeline.
I work primarily on the JVM & the projects (personal/corporate) I work w/ can be summarised as below:
- Building & running the repo is done on the host using an SCM (software configuration management tool) such as Gradle or SBT.
- The external dependencies of the repo, such as Redis, are managed via a
docker-compose.yml. - The README contains a short series of commands to do different tasks RE (1)
However one approach that I’ve always been fond of (& apply/advocate wherever I can) is to replace (3) w/ a
Makefilecontaining a bunch of standard targets shared across all repos, egtest,integration-test. Then Makefiles are thinly customised to fit the repo’s particular repo.This has proven to be very helpful wrt congnitive load (and also CI/CD pipelines): ALL projects, regardless of the toolchain, use the same set of commands, namely
make testmake integration-testmake compose-upmake run
In short (quoting myself here):
Don’t repeat yourself. Make Make make things happen for you!
Since I haven’t heard/read about any bugs, I plan to release v5.0.0 on the 13th (😬)
I’ll keep this post, well, posted 🙂
Recently, I’ve found myself posting more often on Mastodon a Lemmy & blog way less - indeed credits go to Fediverse and the mods for making it a safe and welcoming place ❤
Here’s my latest one: https://www.bahmanm.com/2023/07/firefox-profiles-quickly-replicate-your-settings.html
It’s not self-hosted, rather I’m using Google’s blogspot. I used to host my own website and two dozens of clients’ and friends’ until a few years ago (using Plone and Zope.) But at some point, my priorities changed and I retired my rock-solid installations and switched to blogspot.
I agree w/ you RE posts looking horrible 👍
Though I’d say for one-liners like this, it’s mostly OK. It gets really messy when folks post more complex posts and mention and tag a bunch of times.
I’m afraid I can’t be of any help 😕
Any error logs? Try launching things from the terminal and note down any messages that are printed there.
That’s a good question 💯 In my case too, it took me some time (read years 😂) to figure out what I’m comfortable w/.
I can think of 3 major ways that you can navigate the filesystem while being able to drop to a shell when you need it:
- If you’re familiar w/ Emacs, you can either:
- Use
diredandtrampon your machine to access/navigate the target machine. - Install Emacs (
emacs-nox) on the target machine, SSH and then runemacs-noxand voila! No need fortrampin this scenario.
- Use
- Use Midnight Commander (
mc) which offers a TUI pretty much like Norton Commander (nc) from the days of yore. - Get used to the semi-standard structure of the file system and just use plain Bash (
cd,pushd&popd) to move around. That is- Understand what usually goes into common directories (like
/usr/shareor/opt) and try to follow the same pattern when rolling your own software installations. - Learn how to use your distro’s package manager to query packages and find out where things, like configurations and docs, are stored. Something as simple as
rpm -q --listis what you usually need.
- Understand what usually goes into common directories (like
HTH
- If you’re familiar w/ Emacs, you can either:


{kind=link}
{kind=link}
{kind=link}
I didn’t like the capitalised names so configured xdg to use all lowercase letters. That’s why
~/optfits in pretty nicely.You’ve got a point re
~/.local/optbut I personally like the idea of having the important bits right in my home dir. Here’s my layout (which I’m quite used to now after all these years):$ ls ~ bin desktop doc downloads mnt music opt pictures public src templates tmp videos workspacewhere
binis just a bunch of symlinks to frequently used apps fromoptsrcis where i keep clones of repos (but I don’t do work insrc)workspaceis a where I do my work on git worktrees (based offsrc)